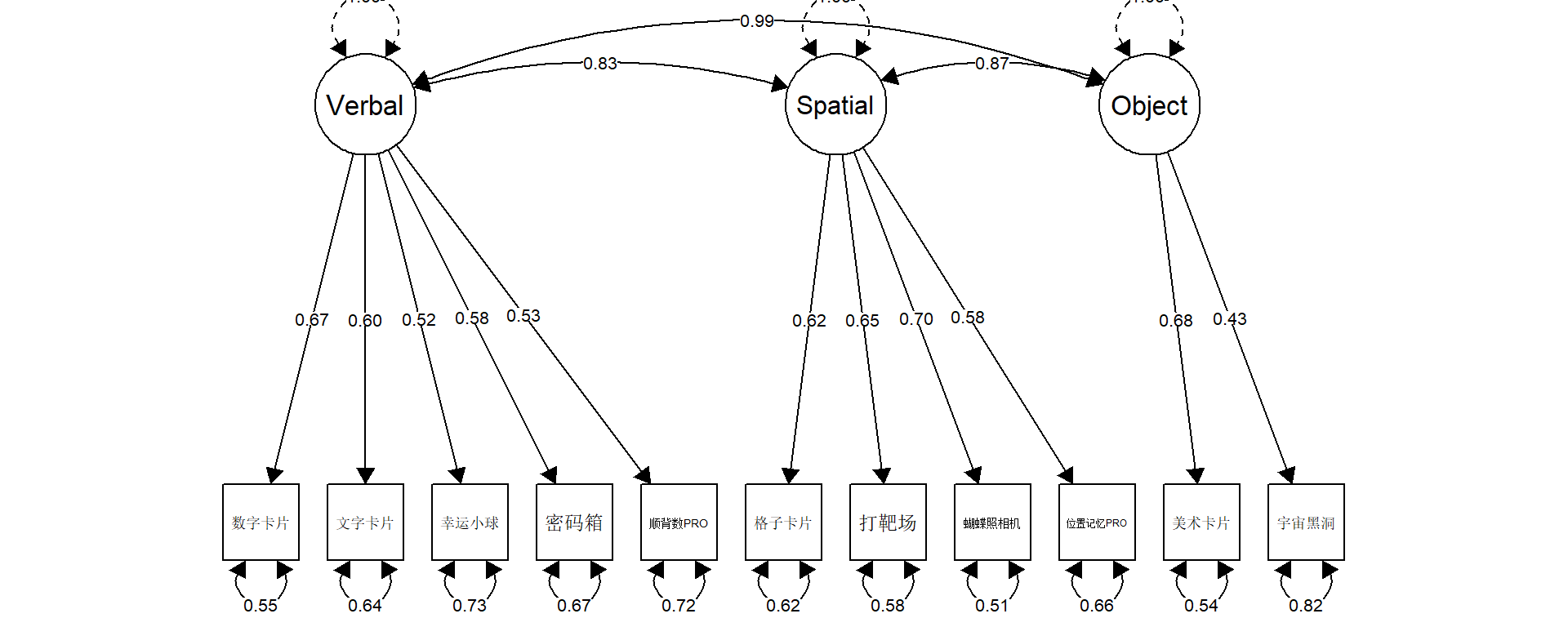
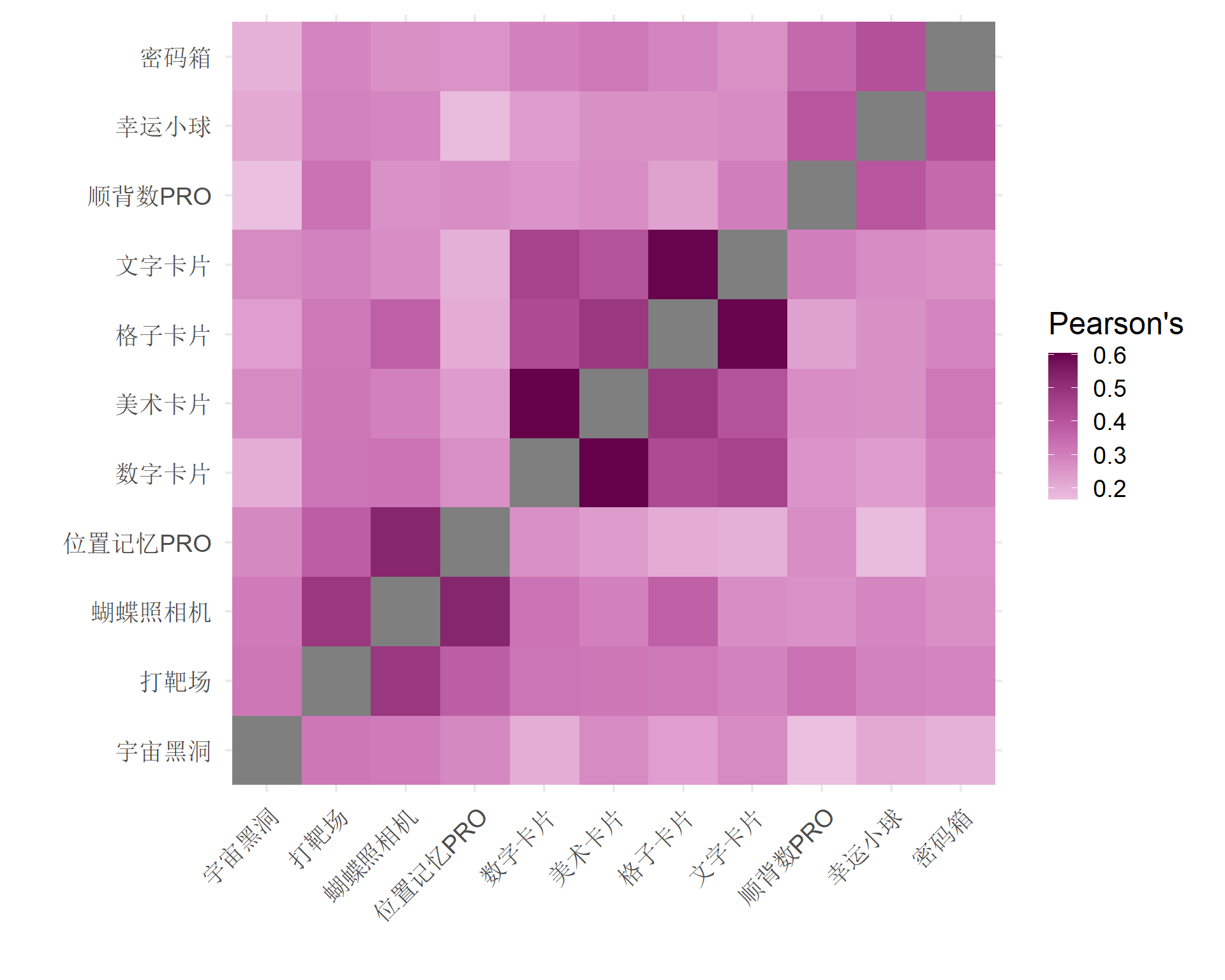
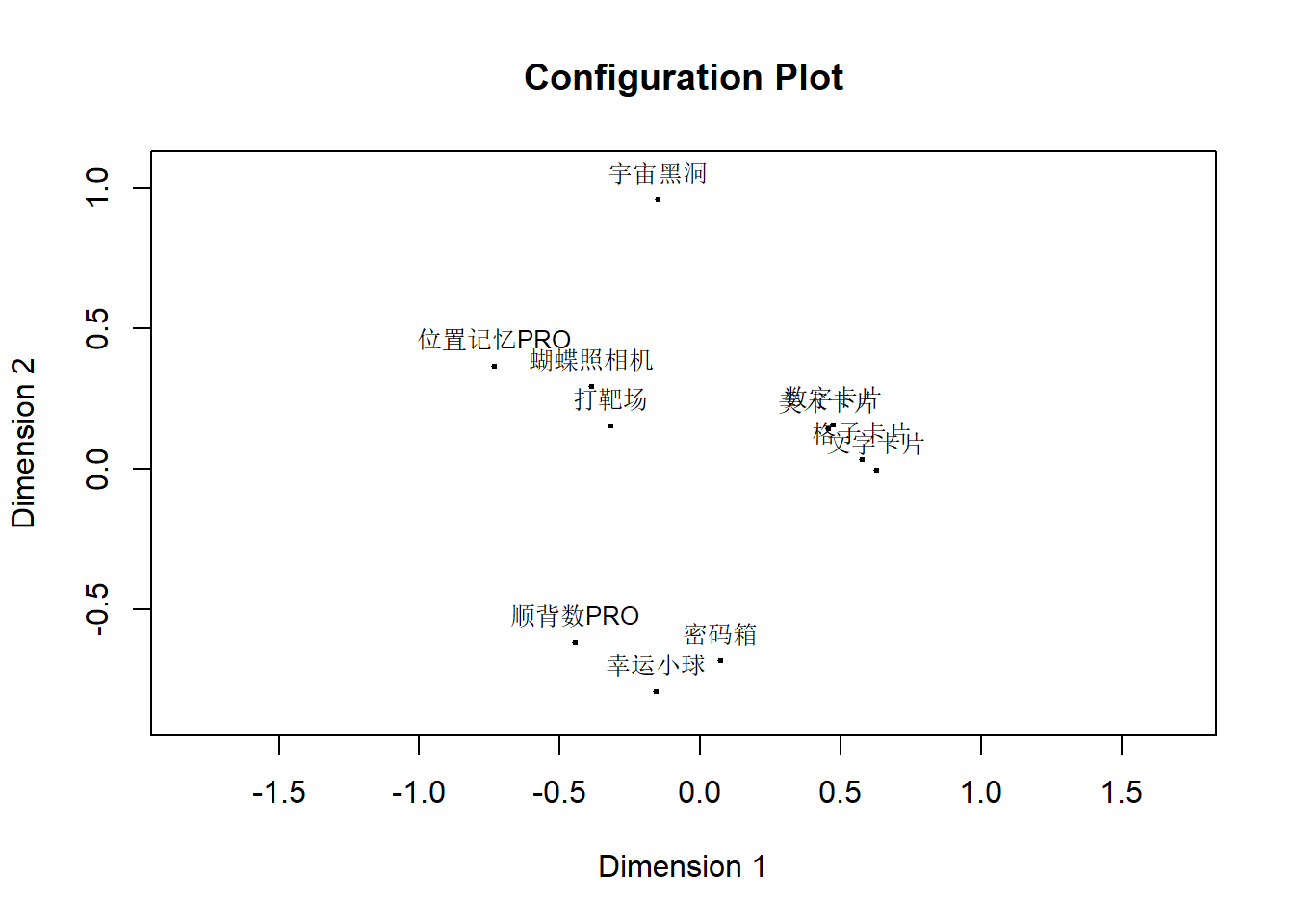
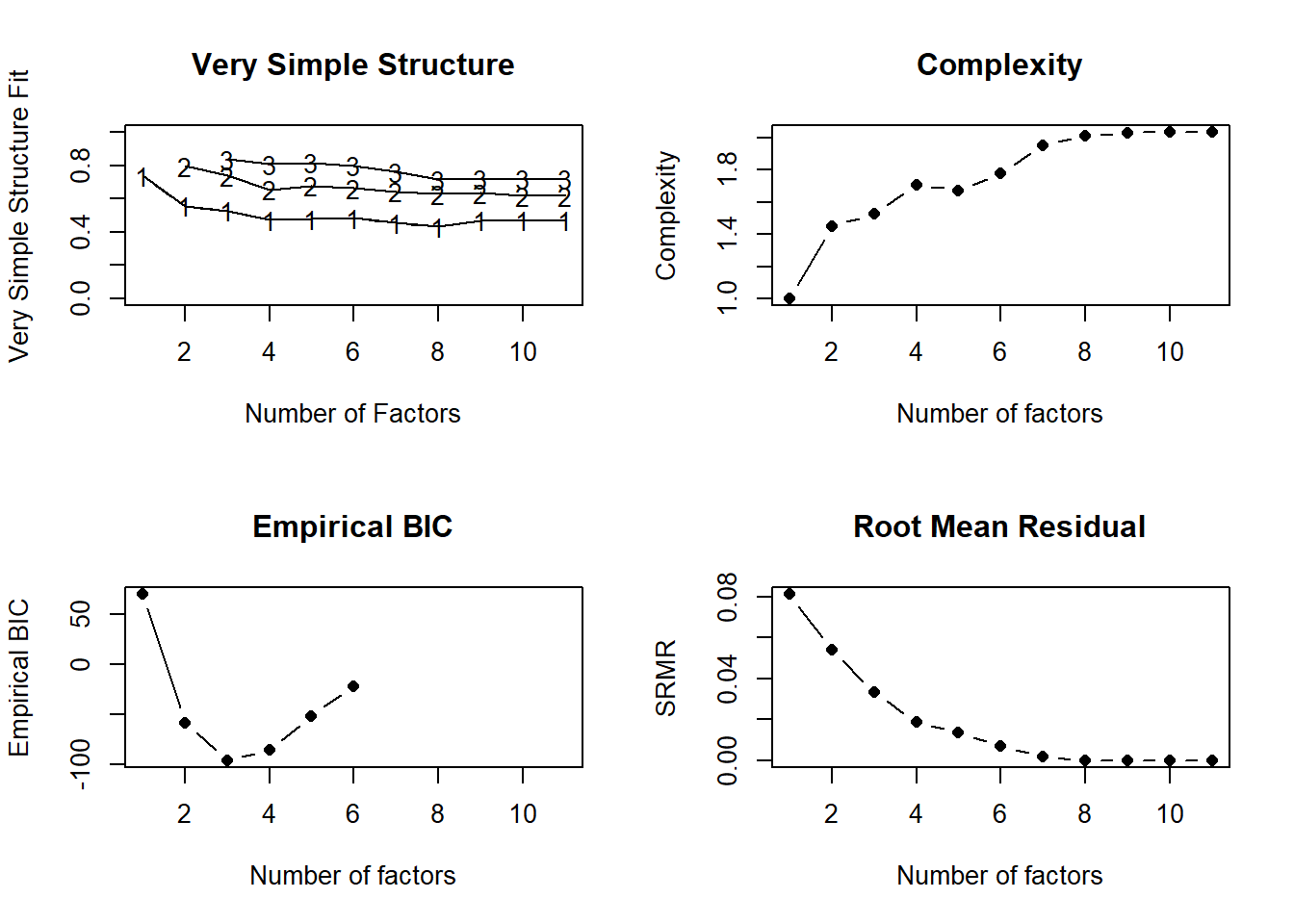
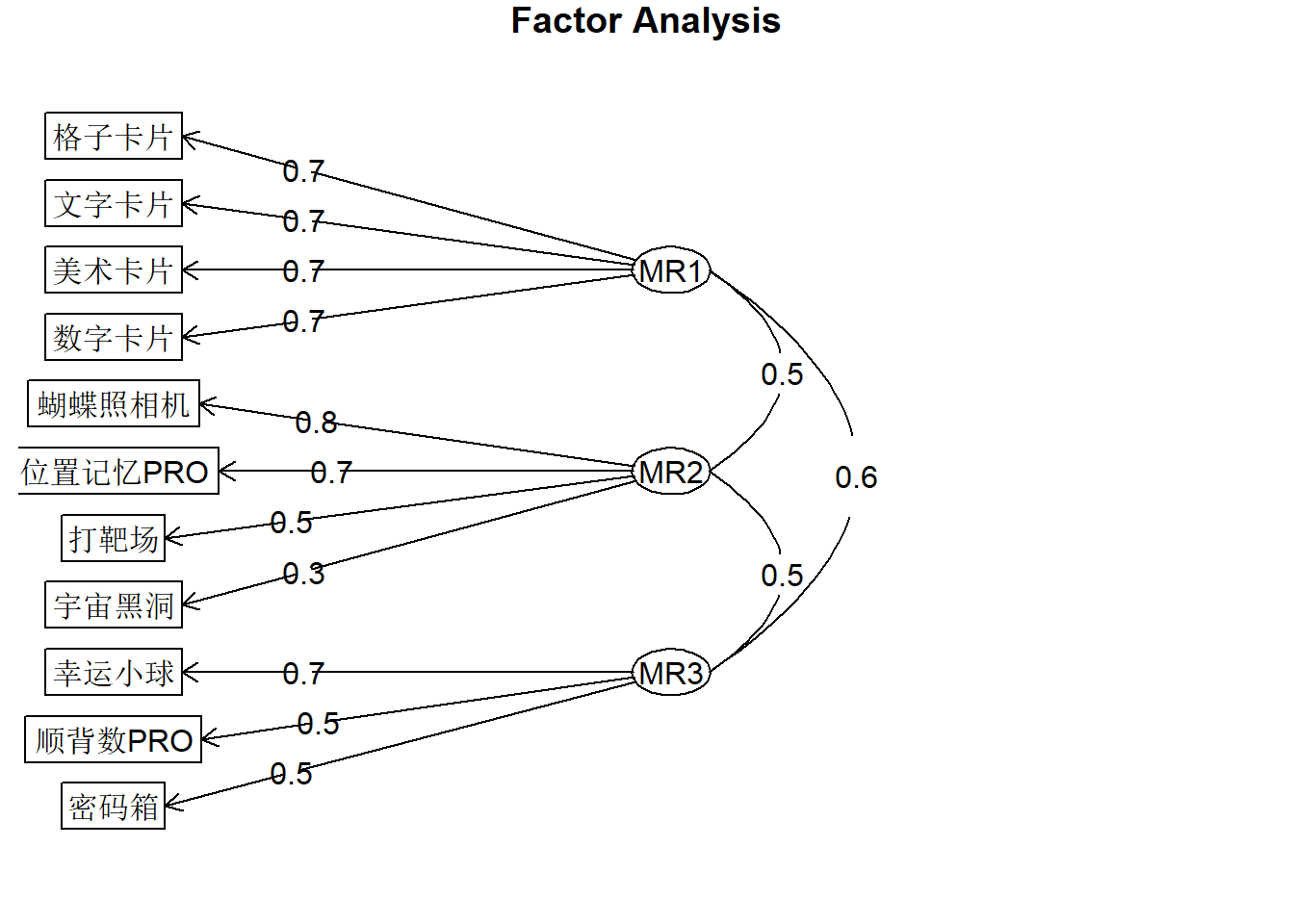
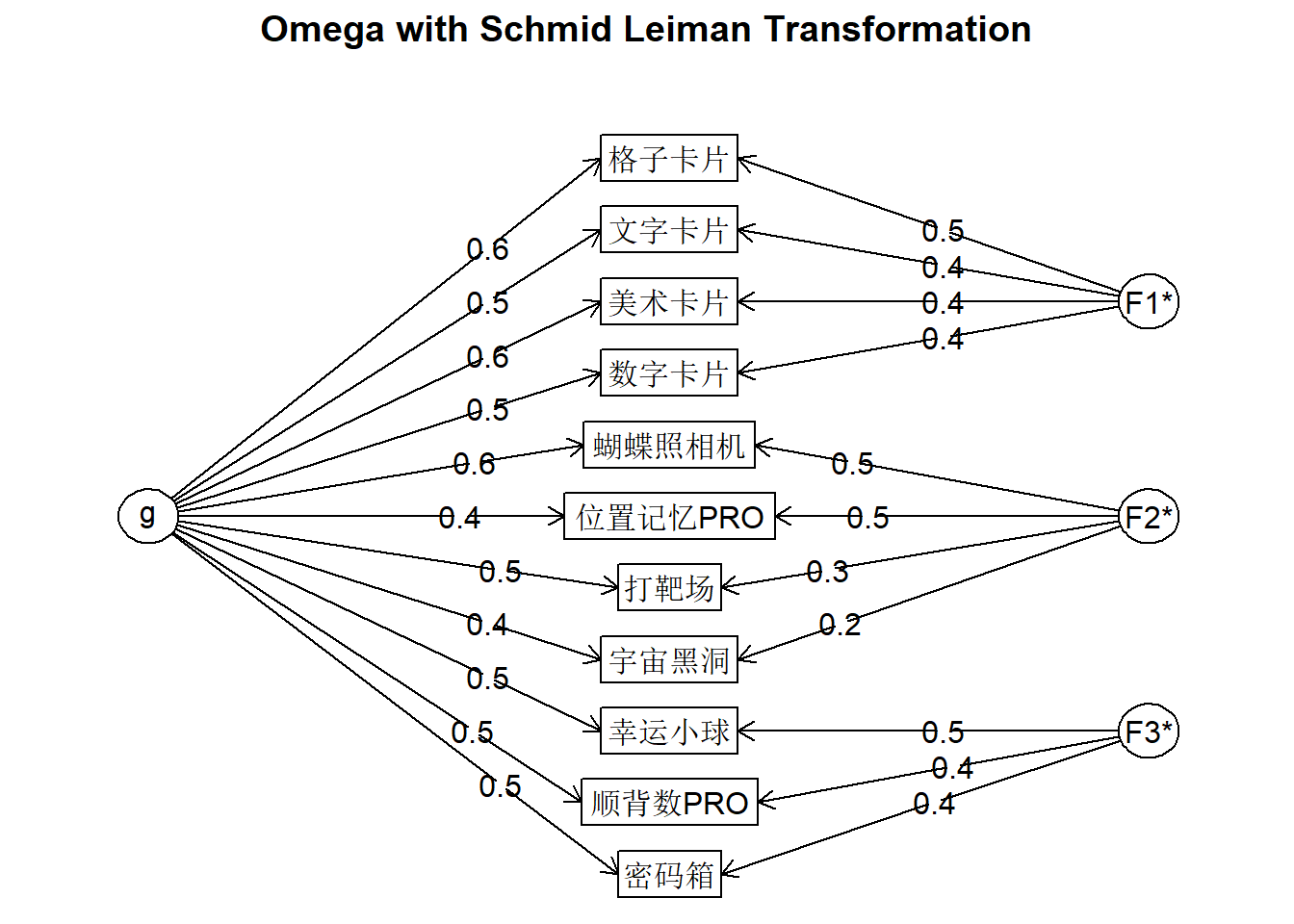
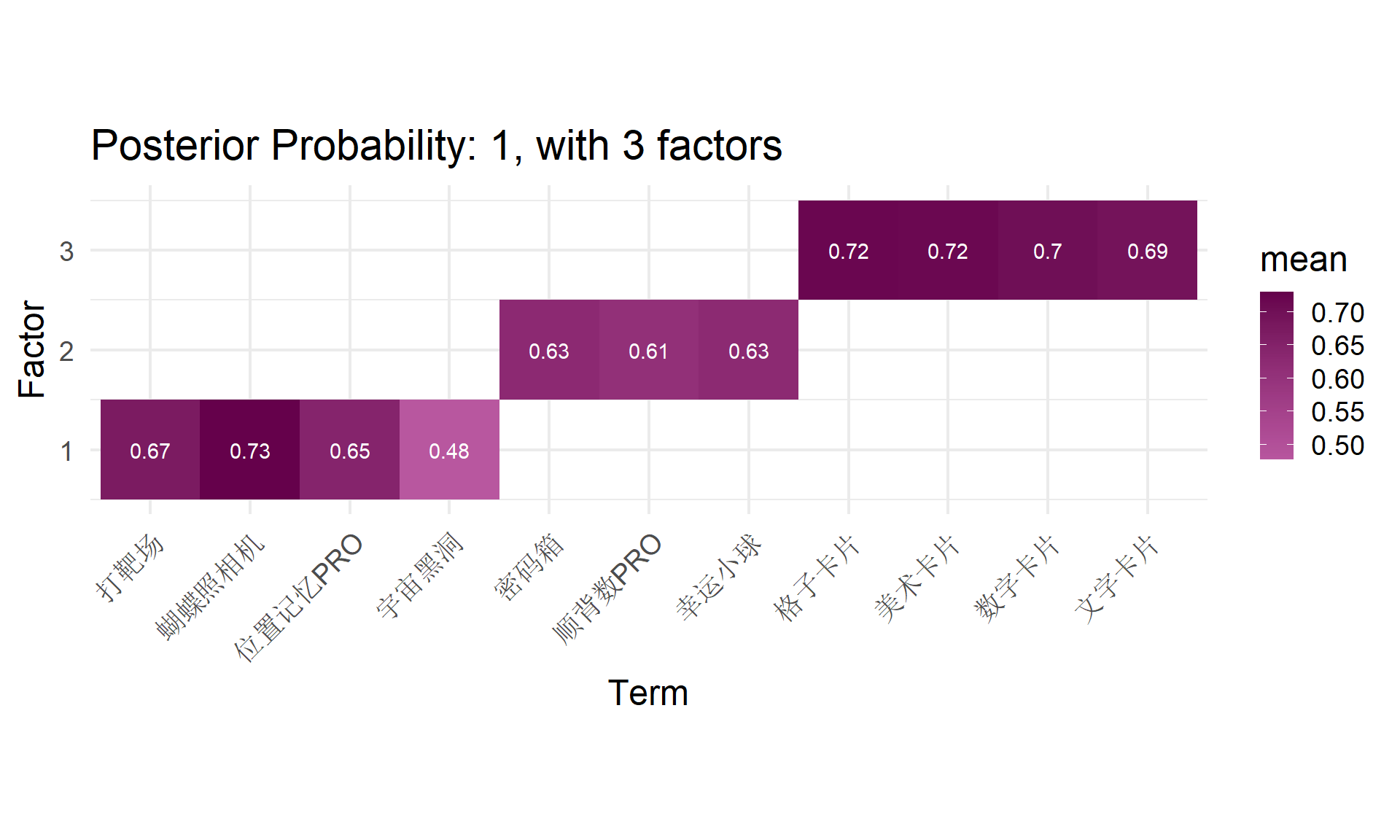
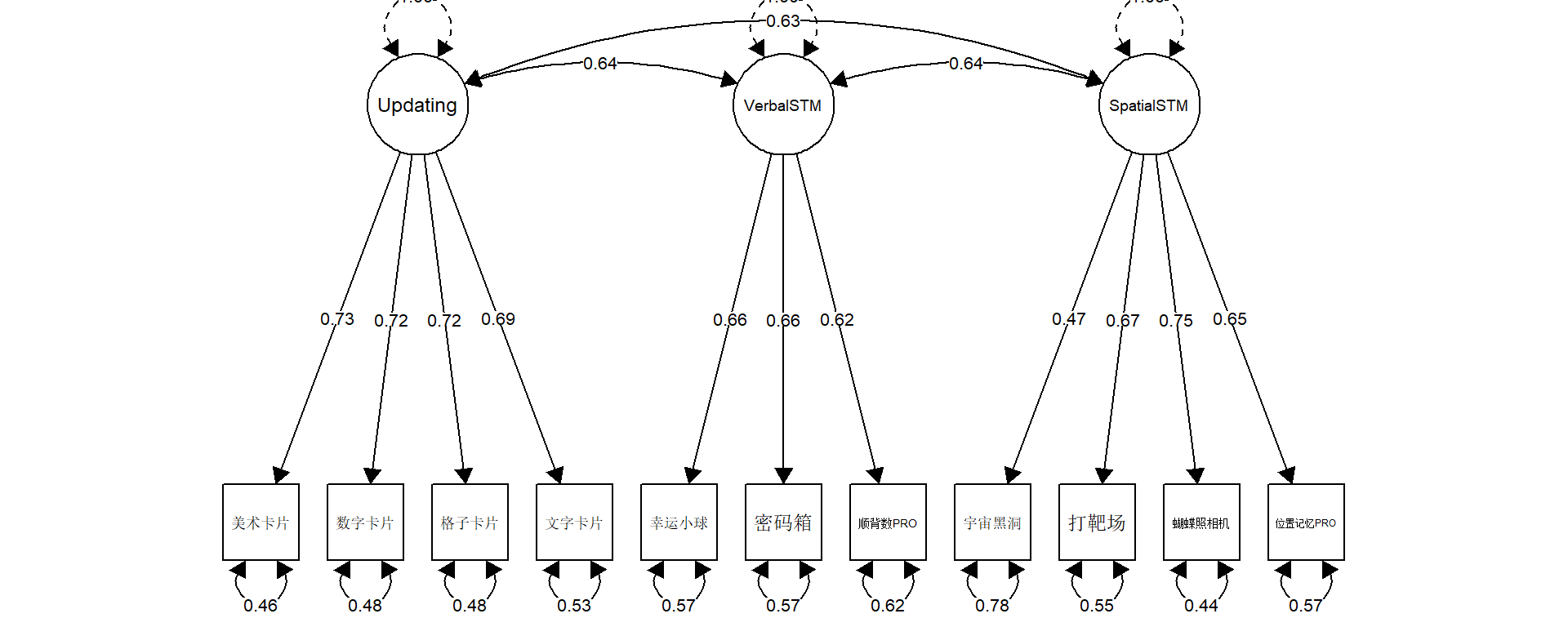
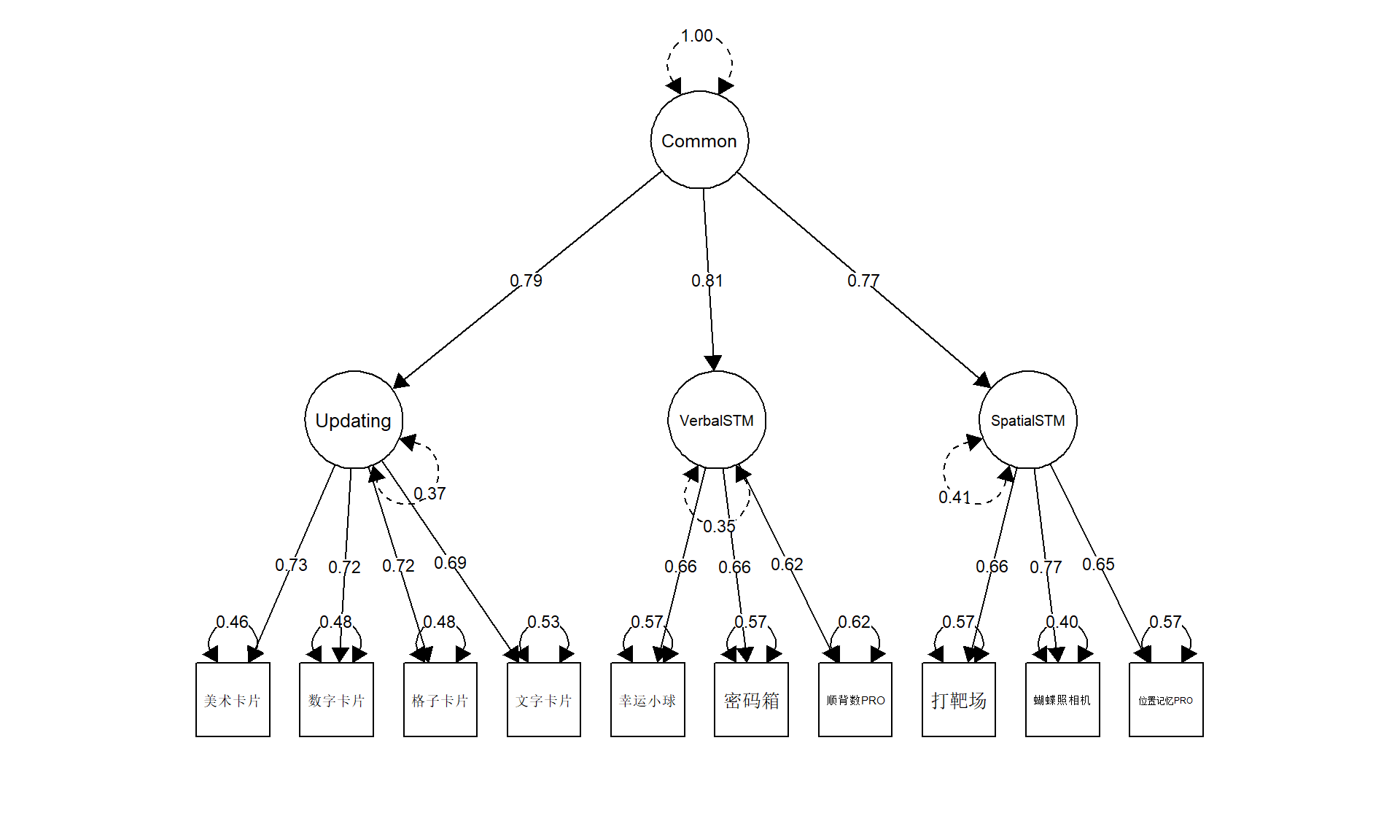
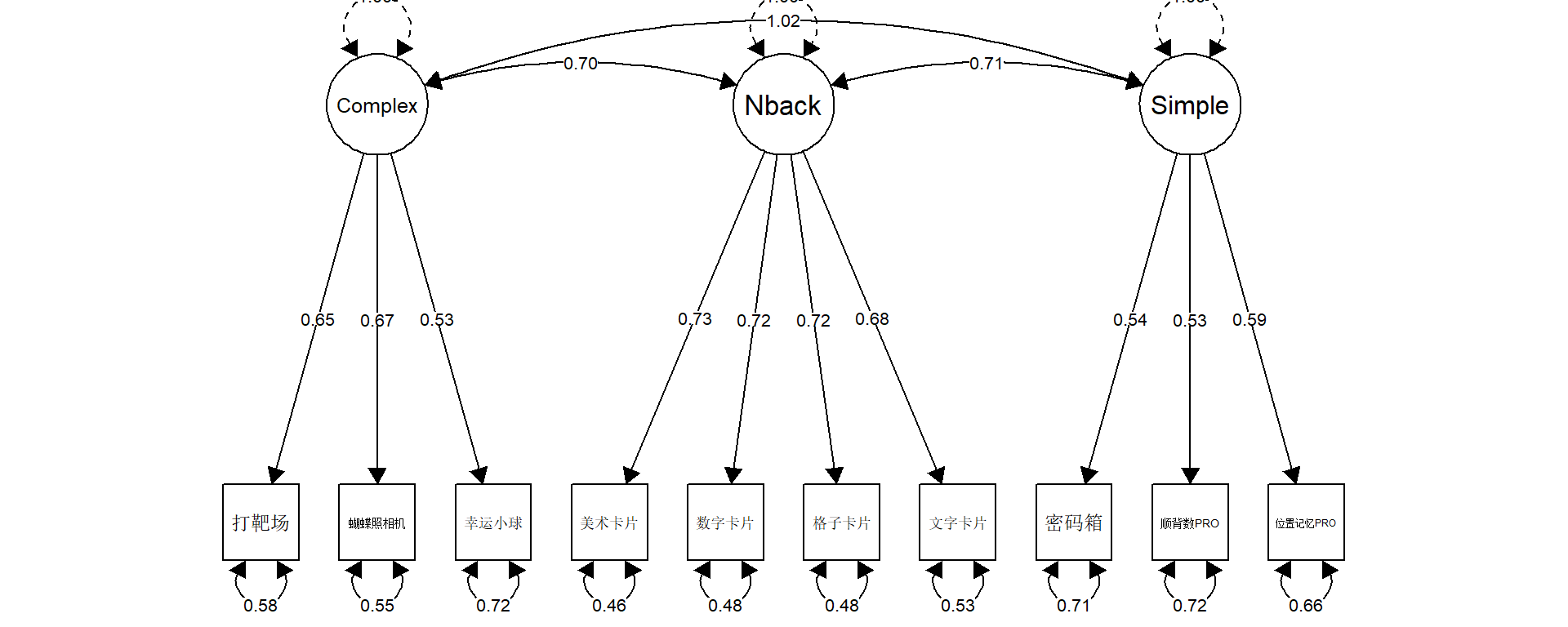
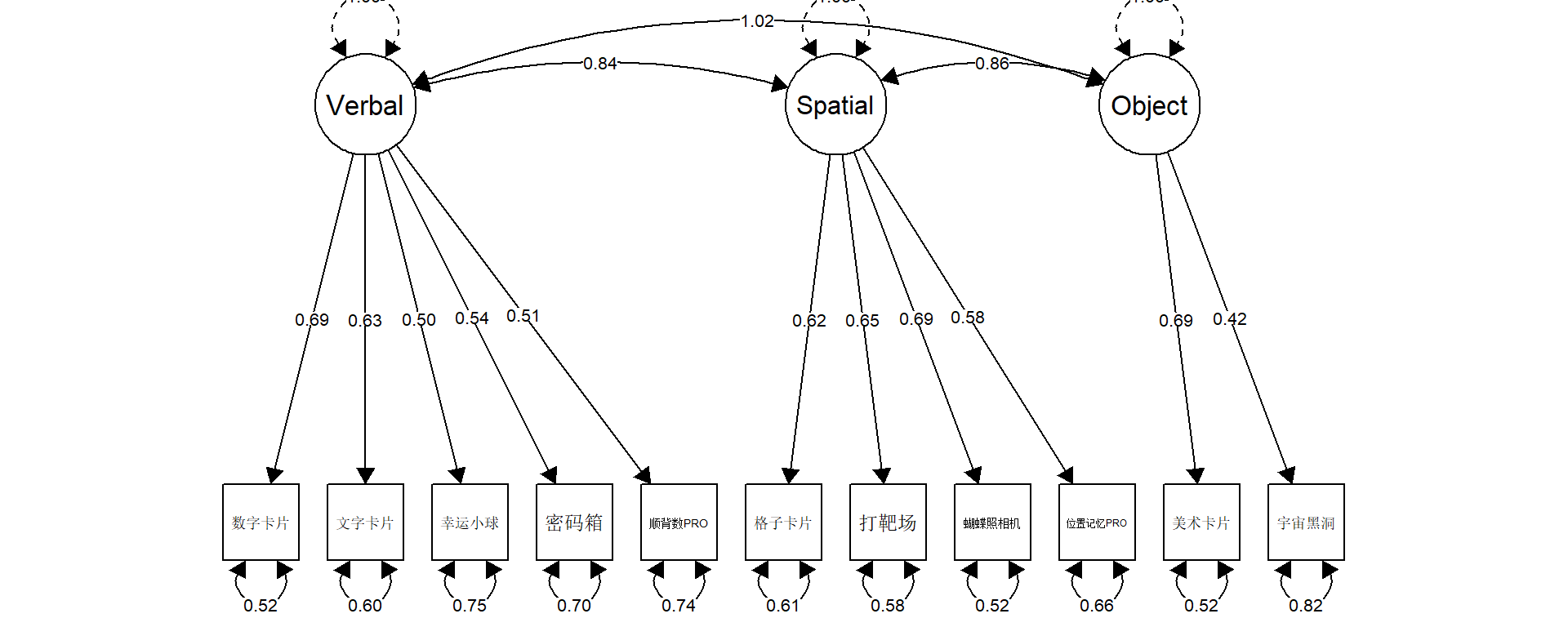
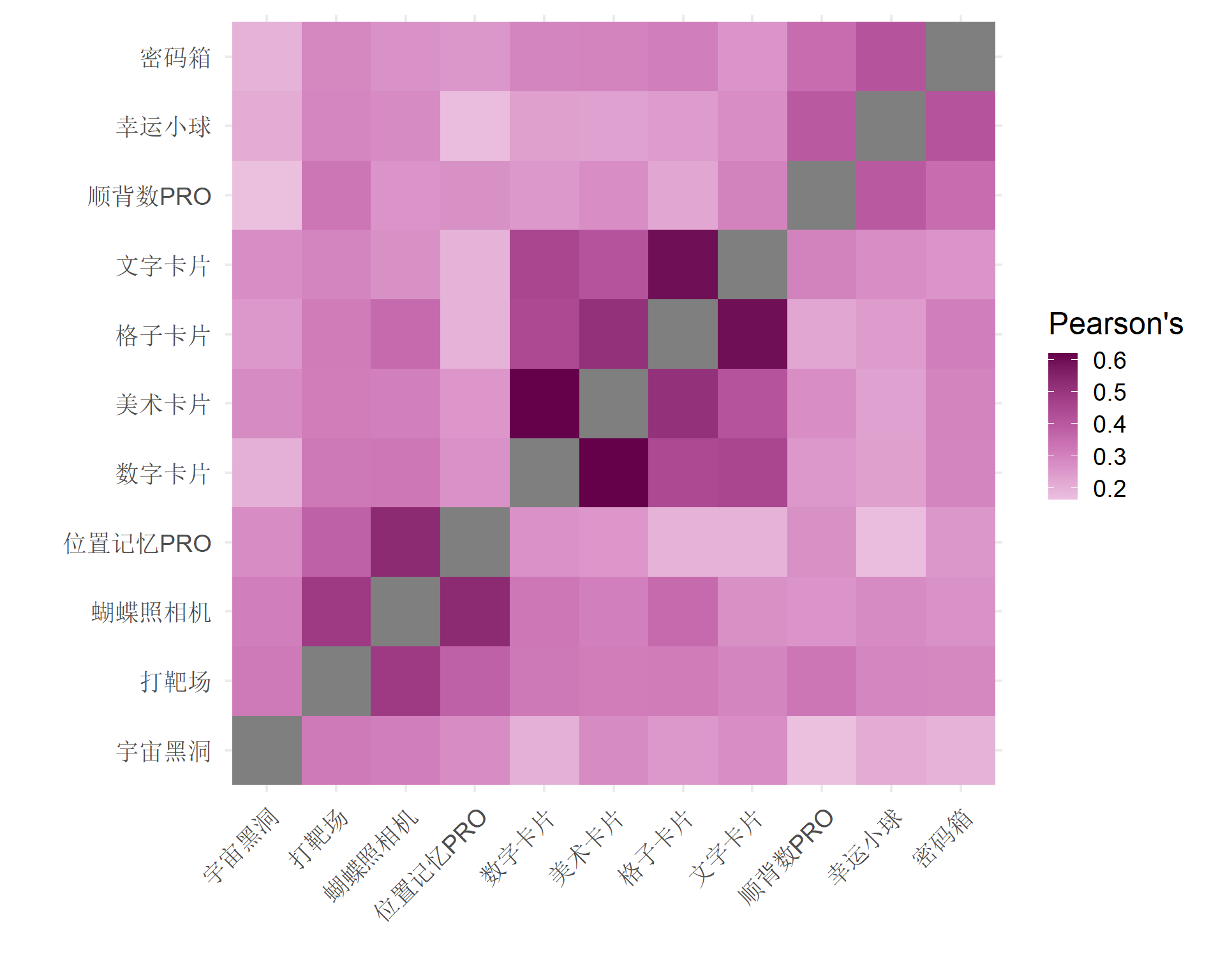
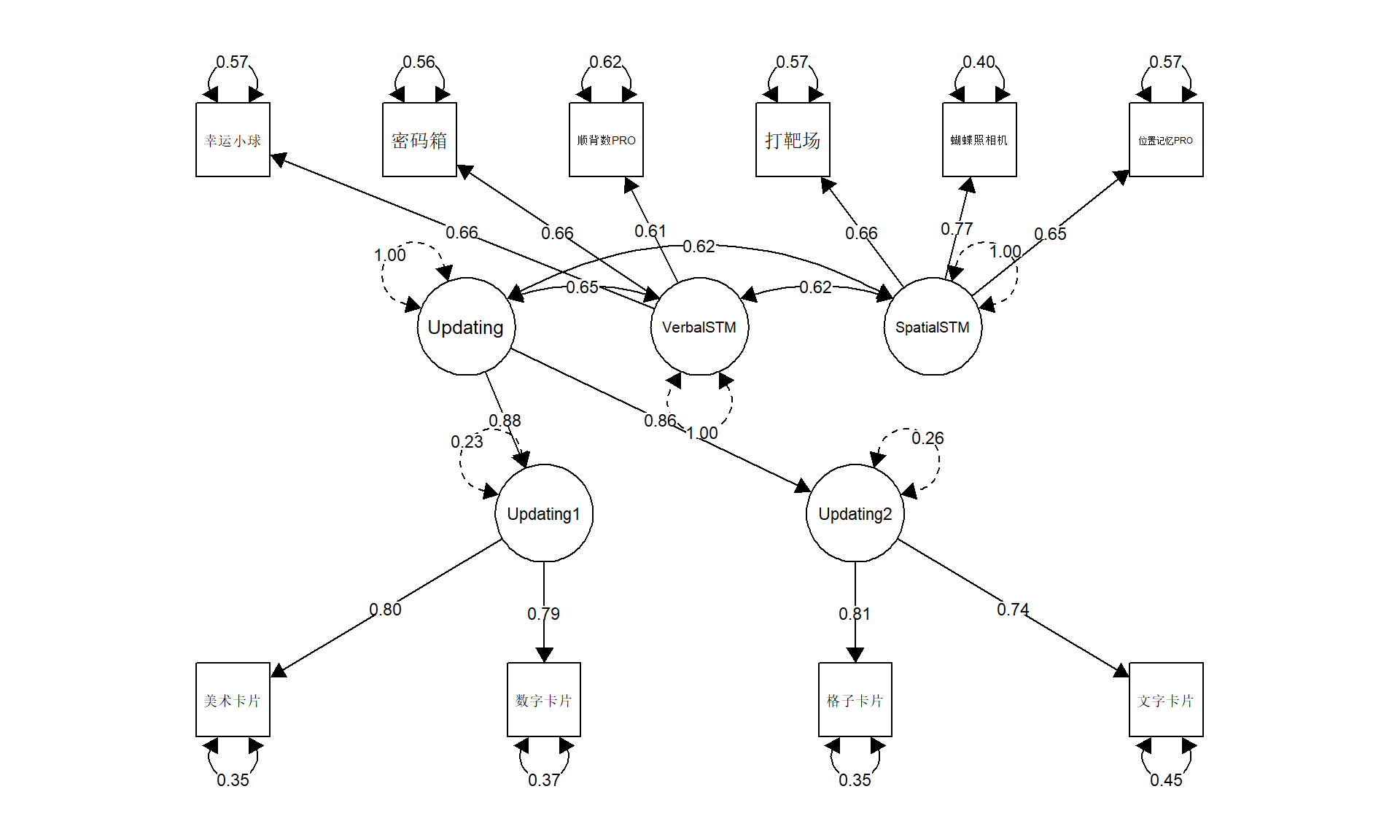
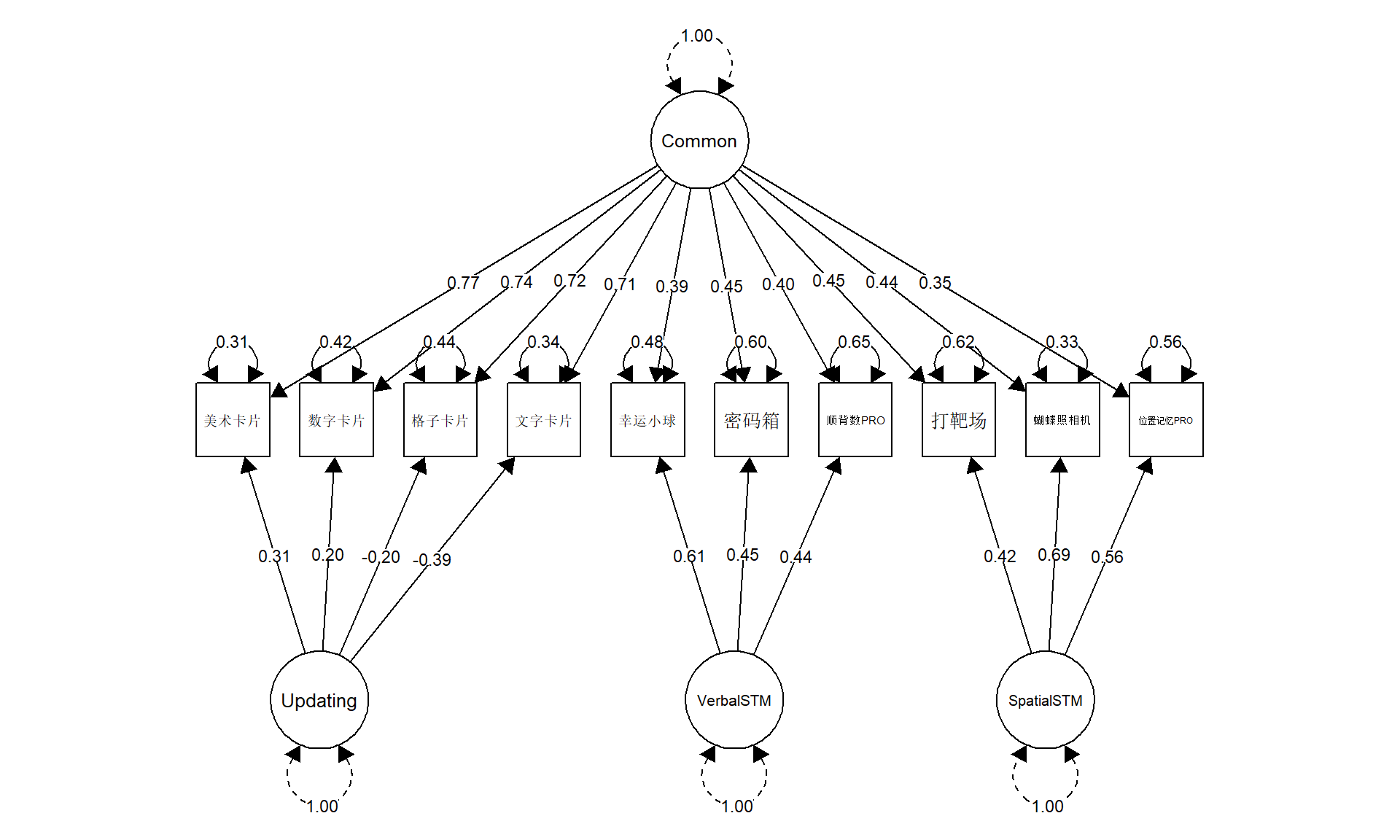
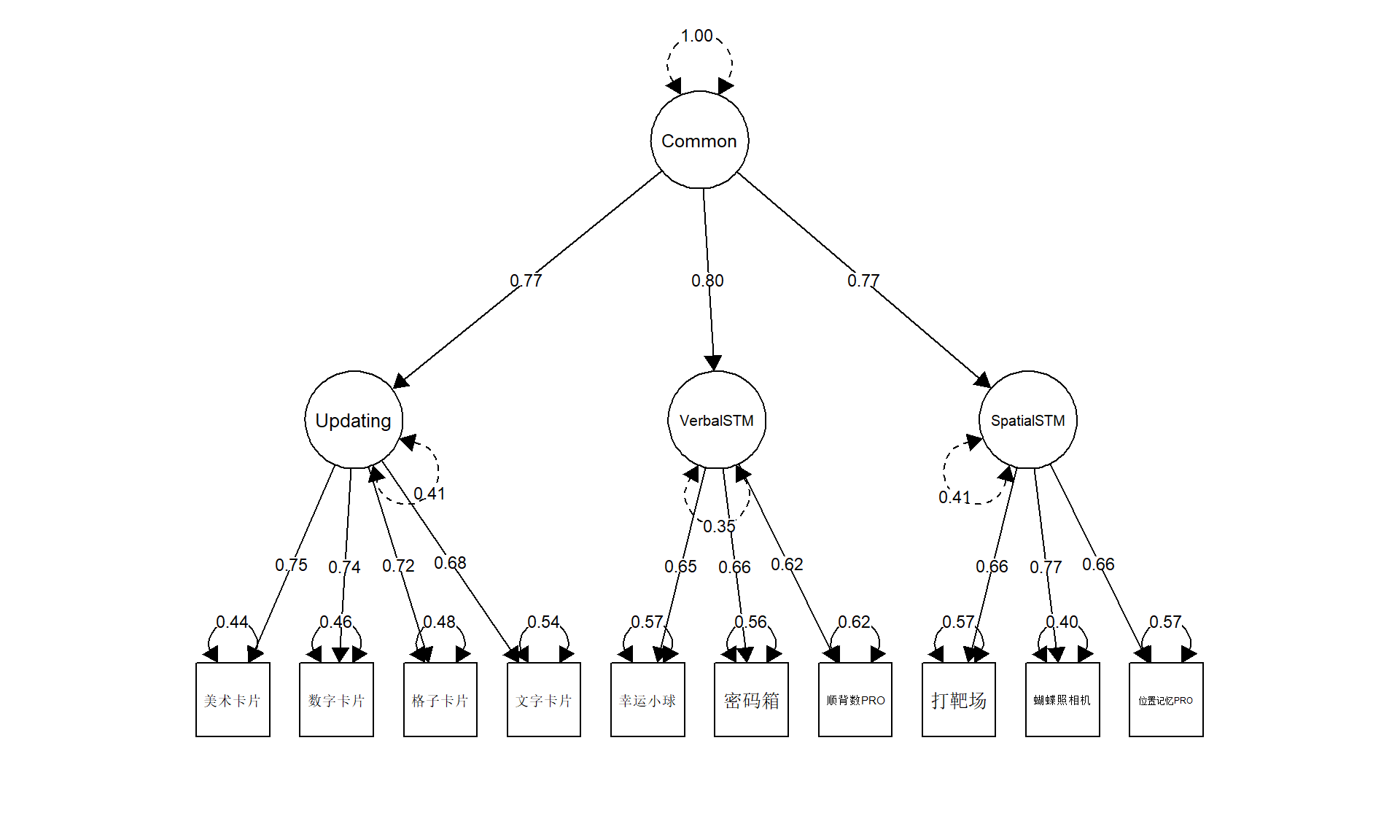
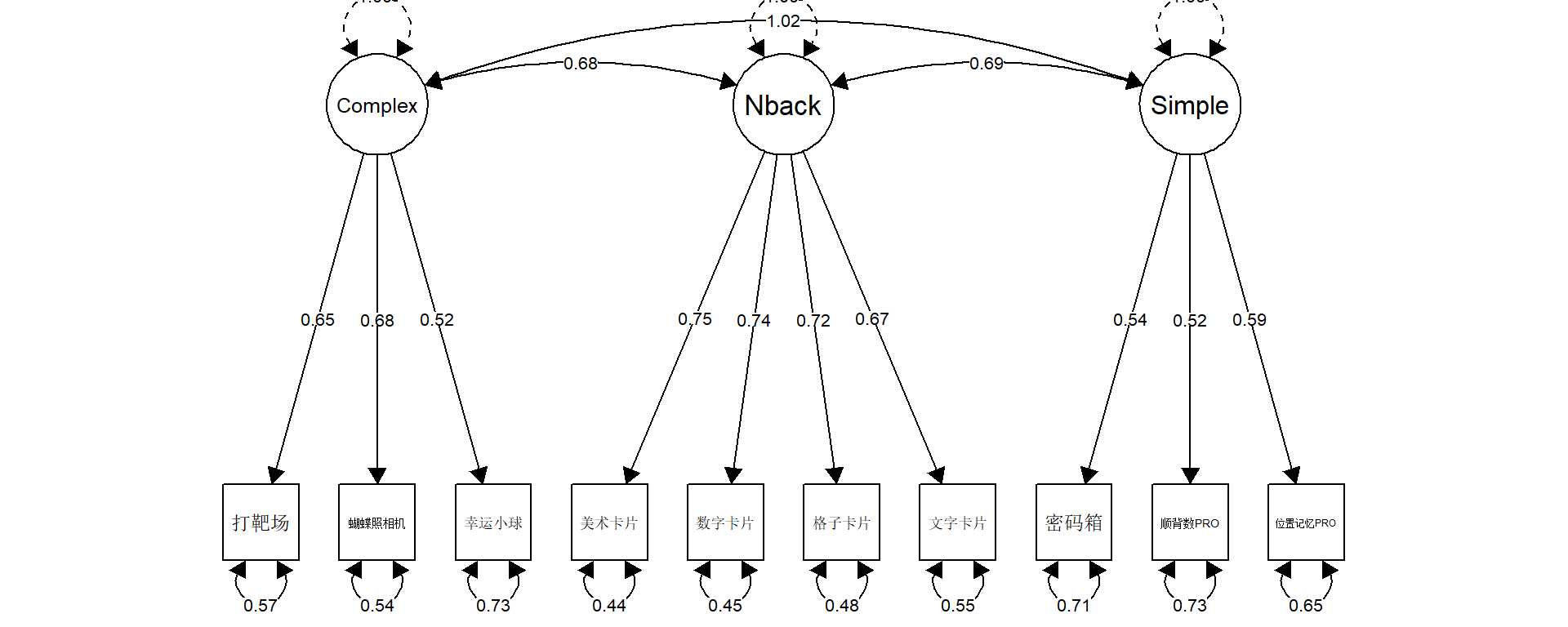
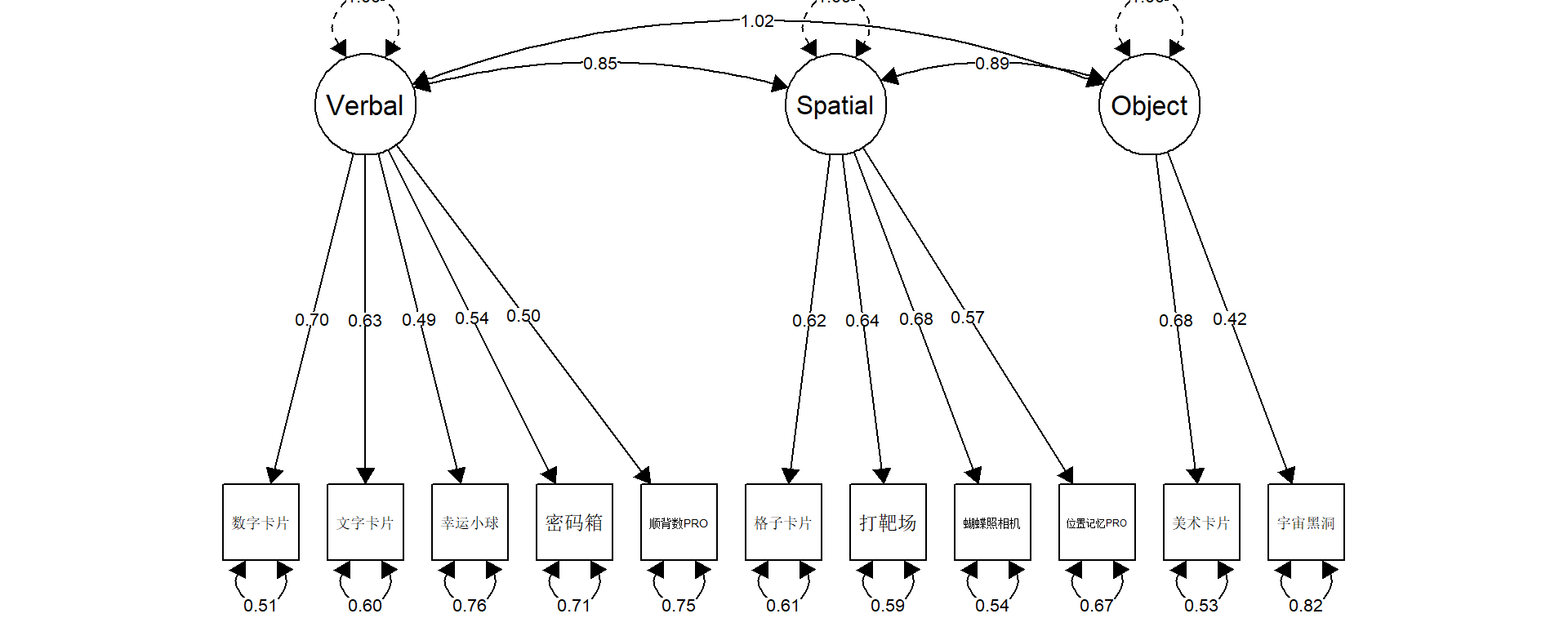
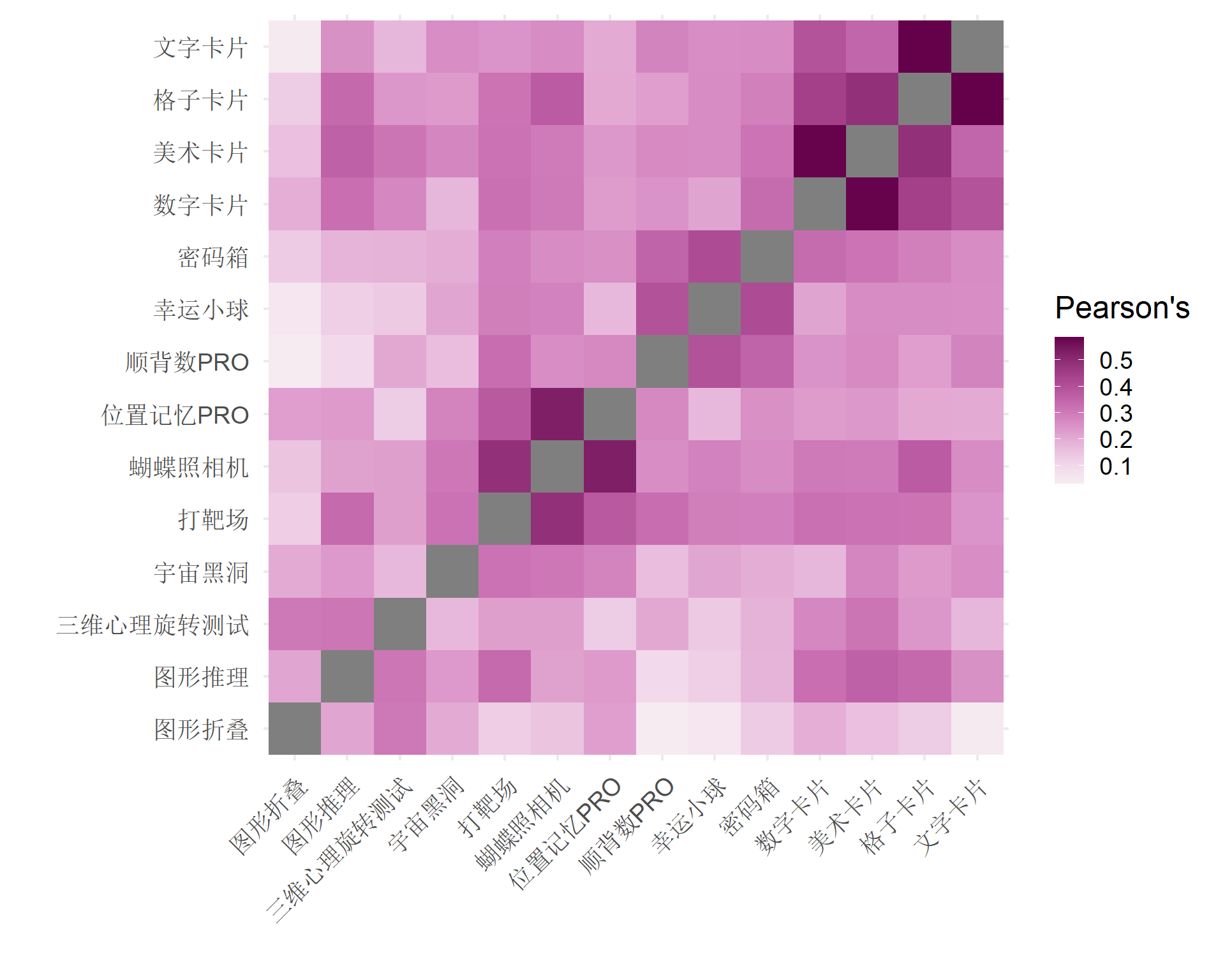
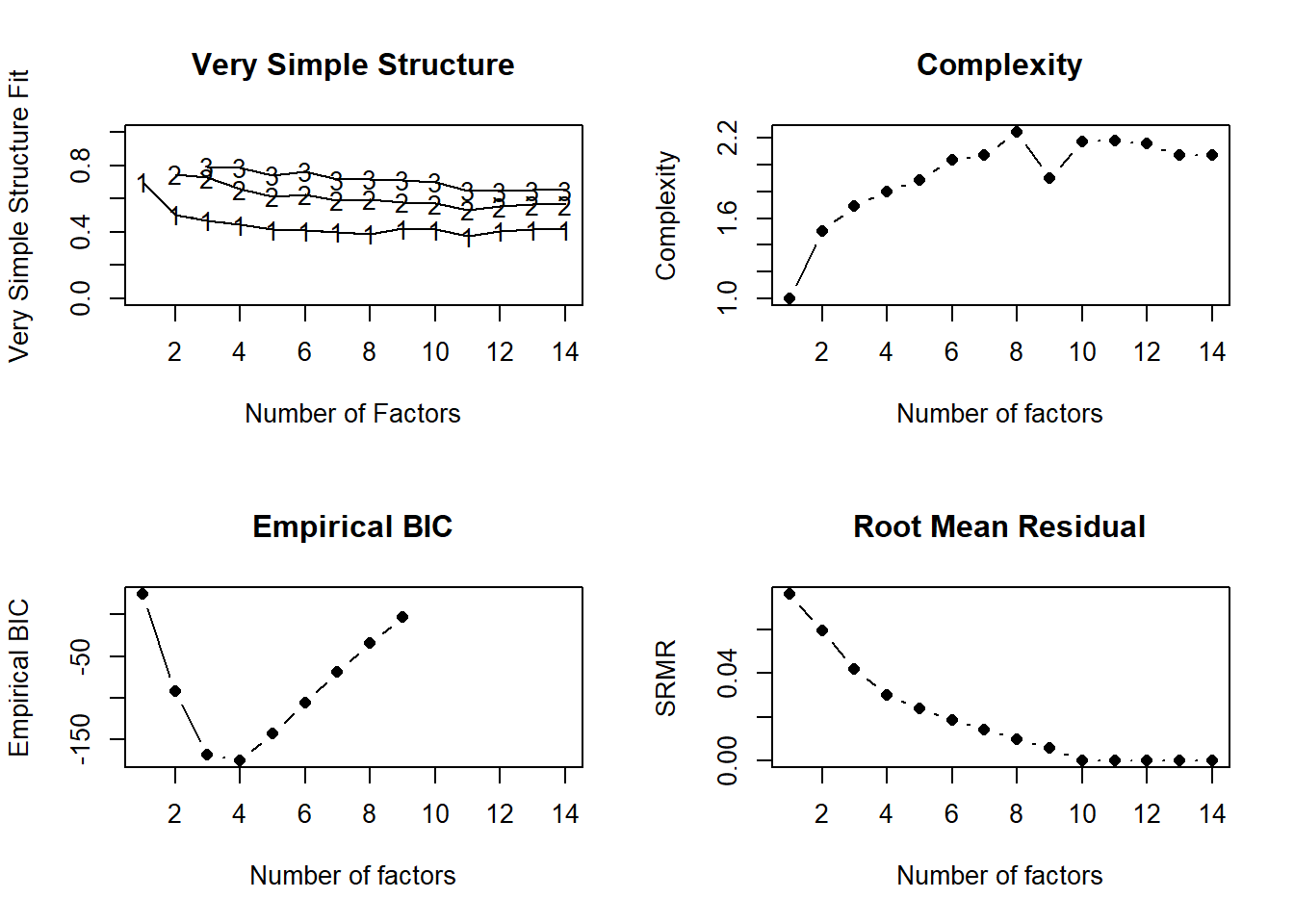
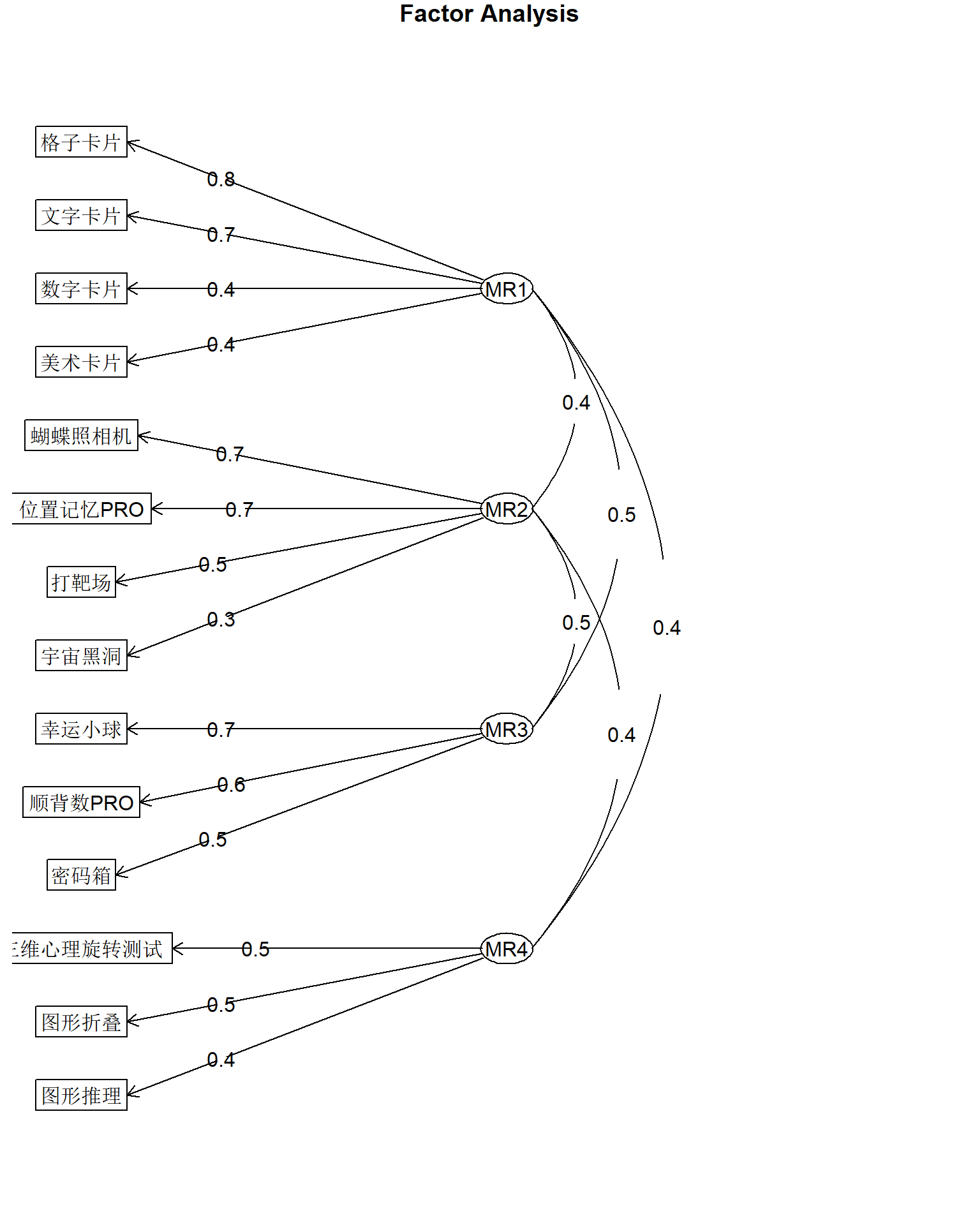
Warning in lav_object_post_check(object): lavaan WARNING: covariance matrix of latent variables
is not positive definite;
use lavInspect(fit, "cov.lv") to investigate.
Warning in lav_object_post_check(object): lavaan WARNING: covariance matrix of latent variables
is not positive definite;
use lavInspect(fit, "cov.lv") to investigate.
Warning in lav_object_post_check(object): lavaan WARNING: covariance matrix of latent variables
is not positive definite;
use lavInspect(fit, "cov.lv") to investigate.
Warning in lav_object_post_check(object): lavaan WARNING: covariance matrix of latent variables
is not positive definite;
use lavInspect(fit, "cov.lv") to investigate.
Warning in lav_object_post_check(object): lavaan WARNING: covariance matrix of latent variables
is not positive definite;
use lavInspect(fit, "cov.lv") to investigate.