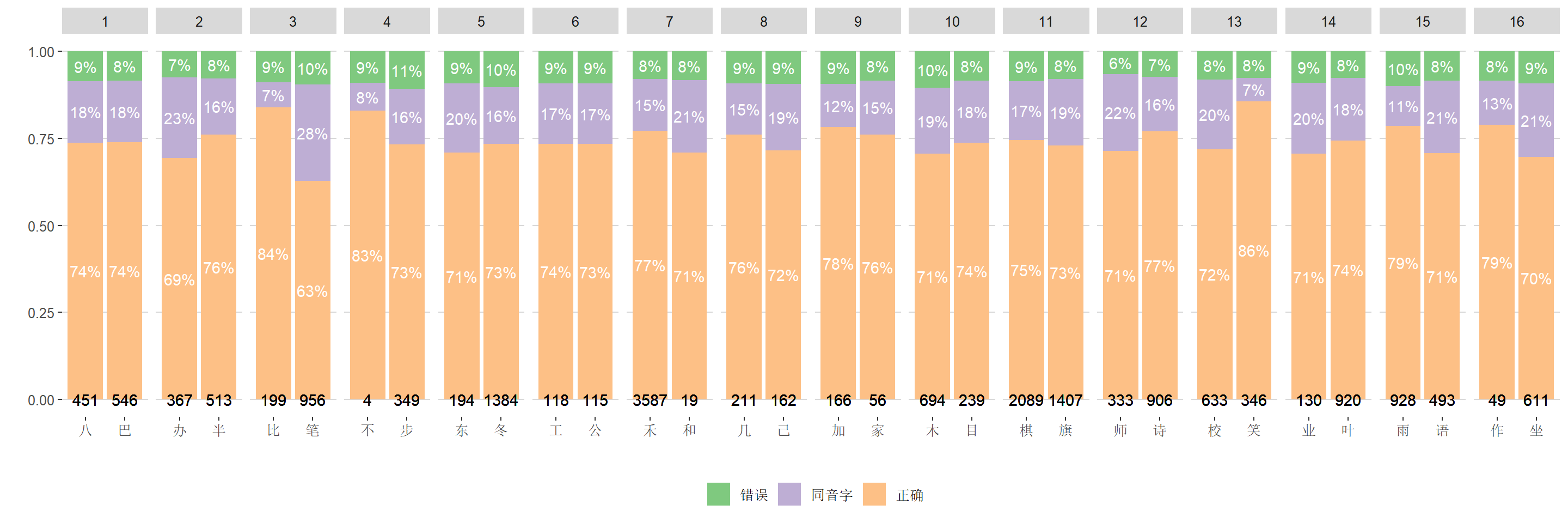
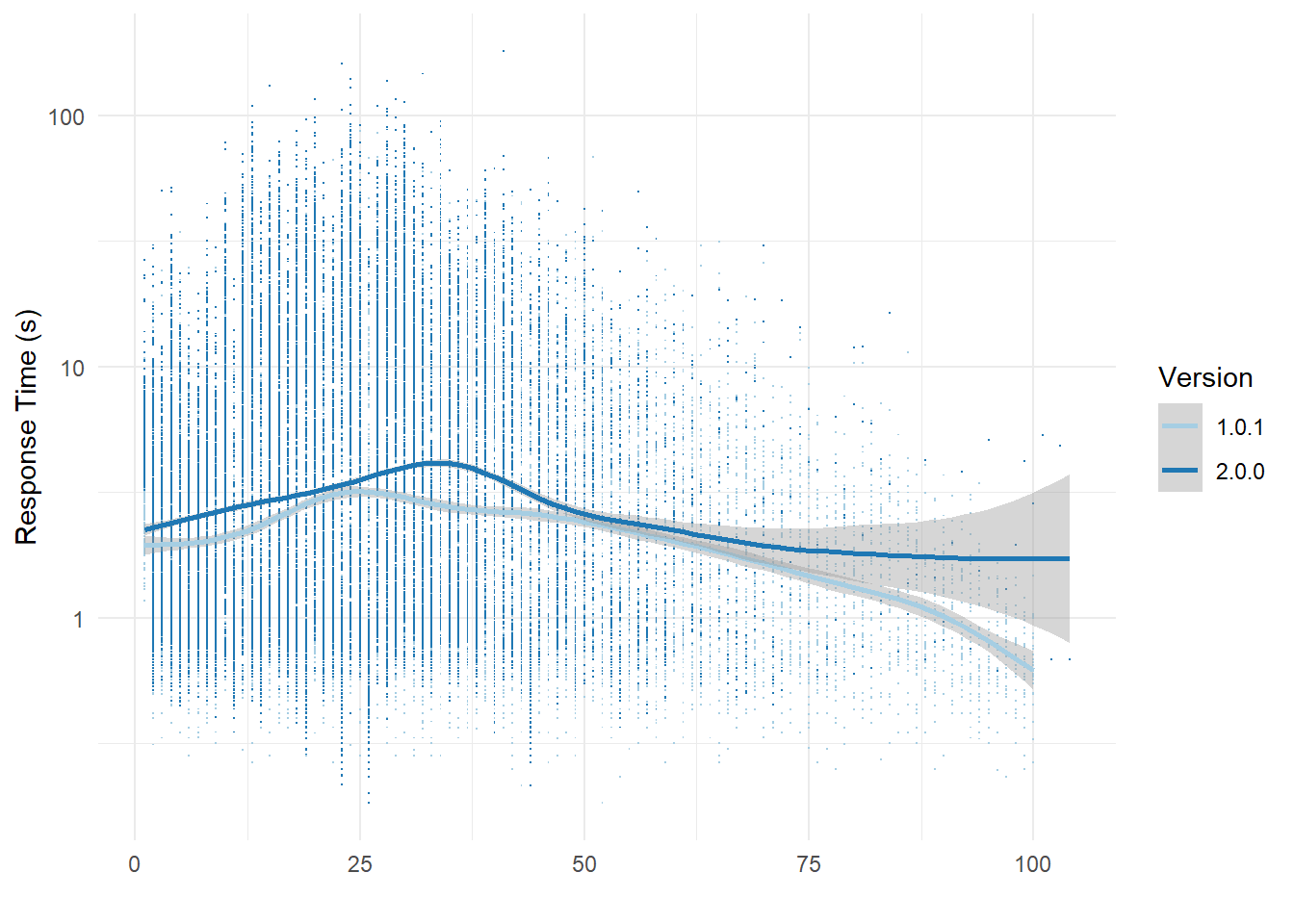
Here we check raw data from several special tasks. Especially check the factors influencing reliability, internal consistency of each task
Forward Word Span (过目不忘)
Code
targets::tar_load(data_valid_FWSPro, store = here::here("preproc/_targets"))
chrs_freq <- read_tsv("CharFreq.txt", skip = 5)
chrs_used <- readxl::read_excel("过目不忘-汉字库.xlsx") |>
left_join(chrs_freq, by = "汉字")
data_adj_acc <- data_valid_FWSPro |>
unnest(raw_parsed) |>
group_by(user_id, game_time) |>
mutate(trial = row_number()) |>
ungroup() |>
mutate(
across(
c(stim, resp),
str_split,
pattern = "-"
)
) |>
unnest(c(stim, resp)) |>
left_join(
select(chrs_used, stim = 汉字, stim_id = ID, stim_freq = 序列号),
by = "stim"
) |>
left_join(
select(chrs_used, resp = 汉字, resp_id = ID),
by = "resp"
) |>
separate(stim_id, c("stim_phon", "stim_form"), convert = TRUE) |>
separate(resp_id, c("resp_phon", "resp_form"), convert = TRUE) |>
mutate(
acc = case_when(
stim == resp ~ "正确",
stim_phon == resp_phon ~ "同音字",
stim_phon != resp_phon ~ "错误"
)
)
data_adj_acc |>
group_by(stim, stim_phon, stim_freq, acc) |>
summarise(n = n(), .groups = "drop_last") |>
mutate(prop = n / sum(n)) |>
ungroup() |>
ggplot(aes(stim, prop, fill = acc)) +
geom_bar(stat = "identity") +
geom_text(
aes(label = scales::label_percent(accuracy = 1)(prop)),
position = position_stack(vjust = 0.5),
color = "white"
) +
geom_text(
aes(label = stim_freq),
y = 0
) +
scale_fill_brewer(palette = "Accent") +
facet_wrap(~ stim_phon, scales = "free_x", nrow = 1) +
labs(x = "", y = "", fill = "") +
# scale_y_continuous(expand = c(0, 0)) +
ggthemes::theme_hc() +
theme(
axis.text.x = element_text(family = "SimHei"),
legend.text = element_text(family = "SimHei")
)
Schulte Grid (舒尔特方格)
Code
targets::tar_load(data_valid_SchulteMed, store = here::here("preproc/_targets"))
rt_by_resp <- data_valid_SchulteMed |>
mutate(
raw_parsed = map(
raw_parsed,
~ . |> mutate(resp = as.integer(resp))
)
) |>
unnest(raw_parsed) |>
group_by(user_id, game_time) |>
mutate(resp_adj = ifelse(acc == 0, NA, resp)) |>
fill(resp_adj, .direction = "up") |>
ungroup() |>
drop_na() |>
group_by(user_id, game_version, game_time, resp_adj) |>
summarise(rt = sum(rt) / 1000, .groups = "drop") |>
filter(rt < 300)
rt_by_resp |>
ggplot(aes(resp_adj, rt, color = game_version)) +
geom_point(shape = ".") +
geom_smooth() +
scale_y_log10() +
scale_color_brewer(palette = "Paired") +
labs(x = "", y = "Response Time (s)", color = "Version") +
theme_minimal()
Reasoning (推理类题目)
Code
targets::tar_load(data_valid_DRA, store = here::here("preproc/_targets"))
data_valid_DRA |>
filter(course_name == "清华大学认知实验D") |>
unnest(raw_parsed) |>
mutate(item = as.numeric(as_factor(itemid))) |>
# group_by(item) |>
# filter(between(mean(acc == 1), 0.6, 0.9)) |>
# ungroup() |>
filter(acc != -1) |>
pivot_wider(
id_cols = user_id,
names_from = item,
values_from = acc
) |>
select(-user_id)
NeuroRacer (小狗回家)
Code
data_racer_new <- targets::tar_read(
data_valid_Racer,
store = here::here("preproc/_targets")
) |>
tidyr::unnest(raw_parsed) |>
dplyr::mutate(block = paste0("V", block)) |>
dplyr::filter(block != "V0")
data_racer_new |>
dplyr::group_by(user_id, block) |>
dplyr::summarise(
mean_score = sum(escortscore * trialdur) / sum(trialdur),
.groups = "drop"
) |>
tidyr::pivot_wider(
id_cols = user_id,
names_from = block,
values_from = mean_score
) |>
dplyr::select(-user_id) |>
psych::alpha()
Reliability analysis
Call: psych::alpha(x = dplyr::select(tidyr::pivot_wider(dplyr::summarise(dplyr::group_by(data_racer_new,
user_id, block), mean_score = sum(escortscore * trialdur)/sum(trialdur),
.groups = "drop"), id_cols = user_id, names_from = block,
values_from = mean_score), -user_id))
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.85 0.85 0.8 0.66 5.7 0.045 0.84 0.043 0.62
95% confidence boundaries
lower alpha upper
Feldt 0.73 0.85 0.92
Duhachek 0.76 0.85 0.94
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
V2 0.75 0.76 0.61 0.61 3.2 0.084 NA 0.61
V3 0.77 0.77 0.62 0.62 3.3 0.081 NA 0.62
V1 0.84 0.85 0.73 0.73 5.5 0.054 NA 0.73
Item statistics
n raw.r std.r r.cor r.drop mean sd
V2 33 0.91 0.89 0.83 0.76 0.84 0.045
V3 33 0.90 0.89 0.82 0.75 0.85 0.055
V1 30 0.83 0.85 0.71 0.66 0.83 0.045
Code
data_racer_new |>
dplyr::group_by(user_id, block) |>
dplyr::group_modify(
~ preproc.iquizoo::cpt(.x)
)|>
dplyr::ungroup() |>
tidyr::pivot_wider(
id_cols = user_id,
names_from = block,
values_from = dprime
) |>
dplyr::select(-user_id) |>
psych::alpha()
Reliability analysis
Call: psych::alpha(x = dplyr::select(tidyr::pivot_wider(dplyr::ungroup(dplyr::group_modify(dplyr::group_by(data_racer_new,
user_id, block), ~preproc.iquizoo::cpt(.x))), id_cols = user_id,
names_from = block, values_from = dprime), -user_id))
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.52 0.53 0.45 0.27 1.1 0.15 2.3 0.55 0.23
95% confidence boundaries
lower alpha upper
Feldt 0.14 0.52 0.75
Duhachek 0.23 0.52 0.81
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
V2 0.37 0.38 0.23 0.23 0.60 0.22 NA 0.23
V3 0.27 0.27 0.15 0.15 0.36 0.25 NA 0.15
V1 0.59 0.60 0.42 0.42 1.48 0.14 NA 0.42
Item statistics
n raw.r std.r r.cor r.drop mean sd
V2 33 0.77 0.73 0.53 0.36 2.4 0.82
V3 33 0.75 0.77 0.60 0.44 2.3 0.69
V1 30 0.64 0.64 0.31 0.22 2.1 0.78
Code
data_racer_old <- targets::tar_read(
data_parsed_Racer,
store = here::here("preproc/_targets")
) |>
dplyr::filter(game_version == "1.0.0") |>
tidyr::unnest(raw_parsed) |>
dplyr::mutate(block = paste0("V", block))
data_racer_old |>
dplyr::group_by(user_id, block) |>
dplyr::summarise(
mean_score = sum(produr * trialdur) / sum(trialdur),
.groups = "drop"
) |>
tidyr::pivot_wider(
id_cols = user_id,
names_from = block,
values_from = mean_score
) |>
dplyr::select(-user_id) |>
psych::alpha()
Reliability analysis
Call: psych::alpha(x = dplyr::select(tidyr::pivot_wider(dplyr::summarise(dplyr::group_by(data_racer_old,
user_id, block), mean_score = sum(produr * trialdur)/sum(trialdur),
.groups = "drop"), id_cols = user_id, names_from = block,
values_from = mean_score), -user_id))
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.098 0.13 0.11 0.028 0.14 0.073 221 80 0.018
95% confidence boundaries
lower alpha upper
Feldt -0.06 0.1 0.24
Duhachek -0.05 0.1 0.24
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
V1 0.162 0.161 0.130 0.046 0.192 0.072 0.00177 0.03686
V2 0.075 0.099 0.079 0.027 0.110 0.077 0.00132 0.01817
V3 0.079 0.106 0.085 0.029 0.118 0.076 0.00137 0.01817
V4 0.028 0.039 0.031 0.010 0.041 0.079 0.00055 0.00446
V5 0.073 0.104 0.087 0.028 0.116 0.076 0.00278 -0.00002
Item statistics
n raw.r std.r r.cor r.drop mean sd
V1 363 0.62 0.43 0.0067 0.0036 310 246
V2 363 0.38 0.47 0.1675 0.0486 197 132
V3 363 0.39 0.47 0.1501 0.0430 192 141
V4 363 0.47 0.52 0.3053 0.0882 200 158
V5 363 0.43 0.47 0.1460 0.0482 205 155
Code
data_racer_old |>
dplyr::group_by(user_id, block) |>
dplyr::group_modify(
~ preproc.iquizoo::cpt(.x)
)|>
dplyr::ungroup() |>
tidyr::pivot_wider(
id_cols = user_id,
names_from = block,
values_from = dprime
) |>
dplyr::select(-user_id) |>
psych::alpha()
Reliability analysis
Call: psych::alpha(x = dplyr::select(tidyr::pivot_wider(dplyr::ungroup(dplyr::group_modify(dplyr::group_by(data_racer_old,
user_id, block), ~preproc.iquizoo::cpt(.x))), id_cols = user_id,
names_from = block, values_from = dprime), -user_id))
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.76 0.76 0.72 0.39 3.2 0.02 2.2 0.6 0.41
95% confidence boundaries
lower alpha upper
Feldt 0.72 0.76 0.8
Duhachek 0.72 0.76 0.8
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
V1 0.73 0.73 0.67 0.40 2.7 0.023 0.0010 0.42
V2 0.70 0.70 0.64 0.37 2.3 0.026 0.0037 0.38
V3 0.71 0.71 0.66 0.38 2.4 0.025 0.0053 0.39
V4 0.72 0.72 0.67 0.39 2.6 0.024 0.0036 0.41
V5 0.72 0.72 0.67 0.39 2.6 0.024 0.0035 0.41
Item statistics
n raw.r std.r r.cor r.drop mean sd
V1 363 0.70 0.69 0.57 0.49 1.6 0.88
V2 363 0.76 0.75 0.66 0.58 2.2 0.91
V3 363 0.73 0.73 0.63 0.55 2.4 0.83
V4 363 0.69 0.70 0.59 0.51 2.4 0.80
V5 363 0.68 0.70 0.59 0.51 2.5 0.76